抱抱脸🤗部署reader服务器版
时隔许久,更新一下发现的白嫖部署阅读服务器版的方法,该方法基于huggingface
第一步当然是注册账号啦(这里提醒,这个网站是处于被墙状态,自行解决哈
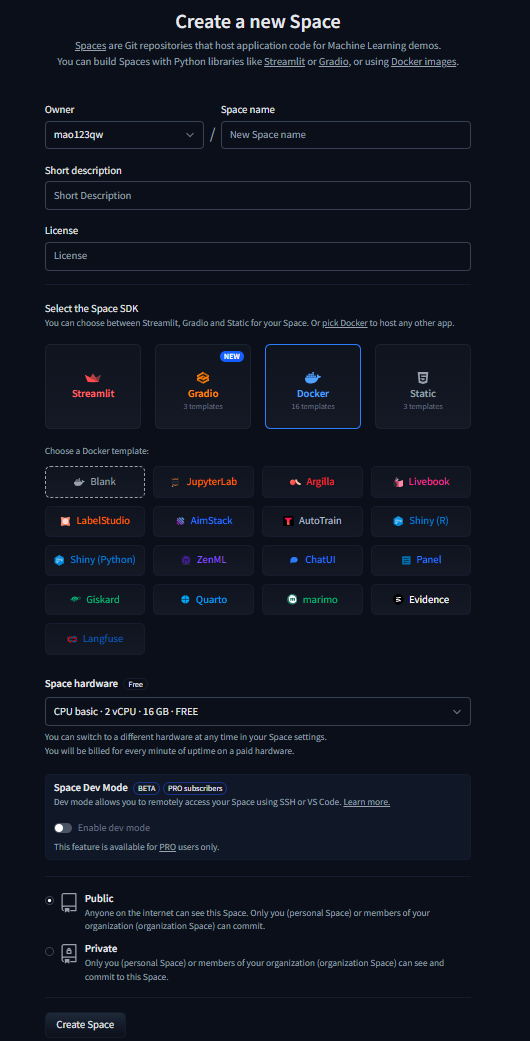
创建一个space
https://huggingface.co/new-space?sdk=docker
自己输入spacename,名字随便,类型选择docker,空间类型选择公开的话后续建议reader,私有空间后续可以用cf workers反代暴露出来
image
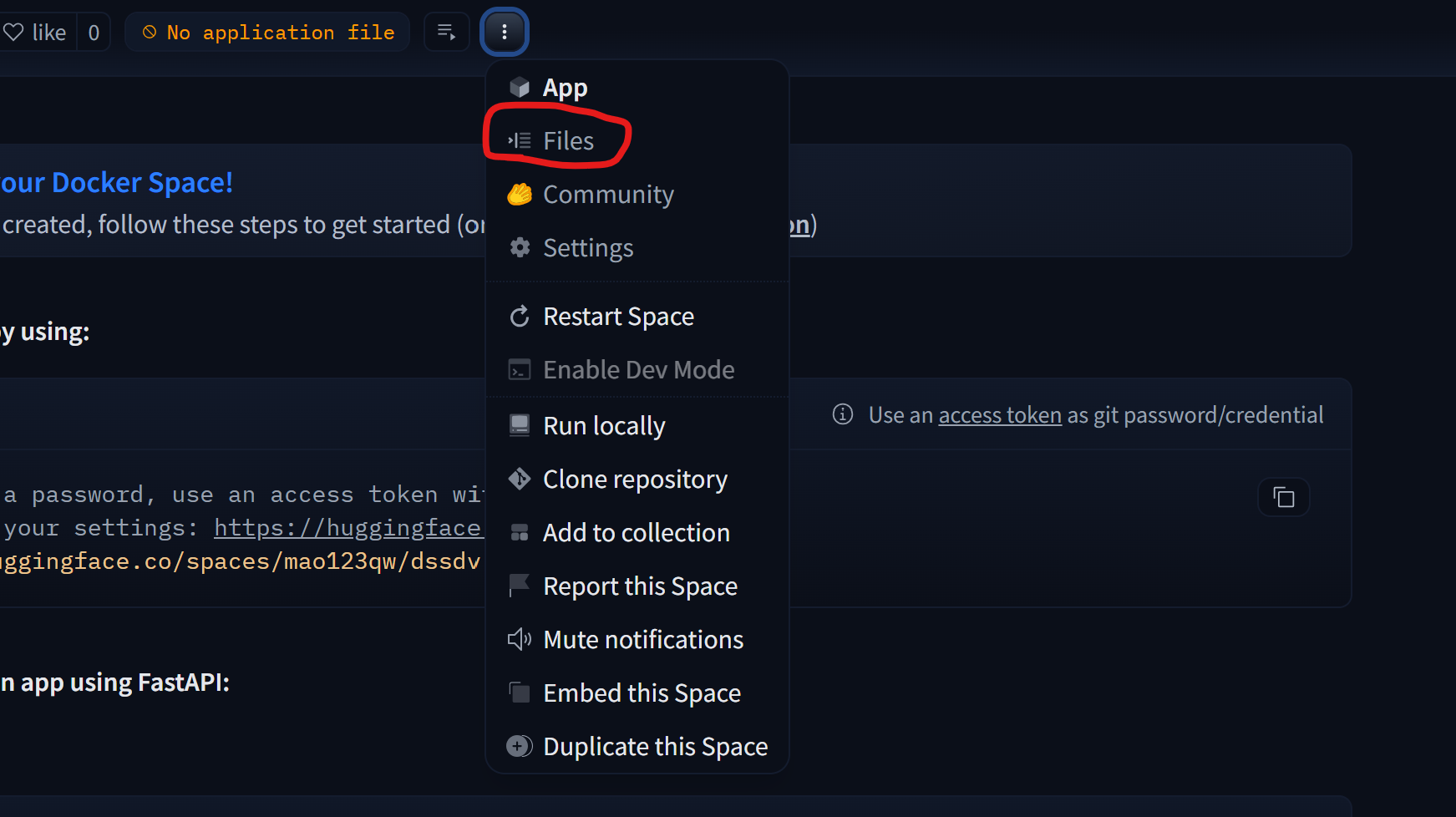
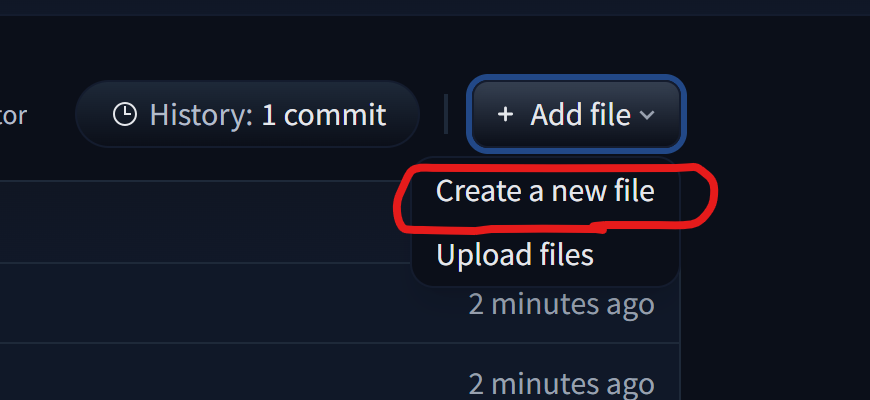
下面新建程序文件
首先点开files界面然后选择新建文件
image
image
新建下面的文件
Dockerfile
# 使用官方Ubuntu基础镜像
FROM ubuntu:22.04
# 设置环境变量
ENV TZ=Asia/Shanghai \
JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 \
APP_USER=reader \
APP_HOME=/app
# 安装依赖并配置环境
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime \
&& echo $TZ > /etc/timezone \
&& apt-get update \
&& apt-get install -y --no-install-recommends \
openjdk-17-jdk \
ca-certificates \
curl \
unzip \
bash \
jq \
python3 \
python3-pip \
python3-venv \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& update-ca-certificates \
&& useradd -r -u 1000 -m -d $APP_HOME -s /bin/bash $APP_USER \
&& chown -R $APP_USER:$APP_USER $APP_HOME
ENV VIRTUAL_ENV=/app/venv
RUN python3 -m venv $VIRTUAL_ENV
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
RUN pip install --no-cache-dir huggingface_hub
# 配置Java环境路径
ENV PATH=$JAVA_HOME/bin:$PATH
ENV LANG C.UTF-8
ENV LC_ALL C.UTF-8
# 设置工作目录和用户
WORKDIR $APP_HOME
USER $APP_USER
# 复制安装脚本并设置权限
COPY --chown=reader:reader install_reader.sh ./
COPY --chown=reader:reader sync_data.sh ./
RUN chmod +x install_reader.sh \
&& sed -i 's|./bin/startup.sh -m single|exec &|' install_reader.sh
RUN chmod +x sync_data.sh
EXPOSE 8080
# 容器入口
CMD ["/bin/sh", "-c", "./sync_data.sh"]
install_reader.sh
#!/bin/bash
set -euo pipefail
# 获取最新版本的重定向URL
echo "正在获取最新版本信息..."
redirect_url=$(curl -Ls -o /dev/null -w '%{url_effective}' 'https://github.com/hectorqin/reader/releases/latest')
# 提取版本标签
tag=$(basename "$redirect_url")
if [[ ! "$tag" =~ ^v[0-9]+\.[0-9]+\.[0-9]+$ ]]; then
echo "错误:无效的版本标签 '$tag'"
exit 1
fi
version="${tag#v}"
echo "检测到最新版本: $version"
# 构造下载链接
download_url="https://github.com/hectorqin/reader/releases/download/${tag}/reader-server-${version}.zip"
echo "开始下载: $download_url"
# 下载文件
if ! curl -LO "$download_url"; then
echo "错误:文件下载失败"
exit 1
fi
# 解压文件
zip_file="reader-server-${version}.zip"
echo "正在解压文件..."
unzip "$zip_file"
#+x
cd target
chmod +x reader-pro-${version}.jar
cd ../bin
# 执行启动脚本
if [ -f "./startup.sh" ]; then
echo "正在启动服务..."
chmod +x "./startup.sh"
./startup.sh -m single
echo "服务已启动!"
tail -f /app/logs/start.out
else
echo "错误:启动脚本不存在"
exit 1
fi
sync_data.sh
#!/bin/sh
# 检查环境变量
if [ -z "$HF_TOKEN" ] || [ -z "$DATASET_ID" ]; then
echo "Starting without backup functionality - missing HF_TOKEN or DATASET_ID"
exit 1
fi
# 激活虚拟环境
. /app/venv/bin/activate
# 上传备份
cat > hf_sync.py << 'EOL'
from huggingface_hub import HfApi
import sys
import os
import tarfile
import tempfile
def manage_backups(api, repo_id, max_files=50):
files = api.list_repo_files(repo_id=repo_id, repo_type="dataset")
backup_files = [f for f in files if f.startswith('backup_') and f.endswith('.tar.gz')]
backup_files.sort()
if len(backup_files) >= max_files:
files_to_delete = backup_files[:(len(backup_files) - max_files + 1)]
for file_to_delete in files_to_delete:
try:
api.delete_file(path_in_repo=file_to_delete, repo_id=repo_id, repo_type="dataset")
print(f'Deleted old backup: {file_to_delete}')
except Exception as e:
print(f'Error deleting {file_to_delete}: {str(e)}')
def upload_backup(file_path, file_name, token, repo_id):
api = HfApi(token=token)
try:
api.upload_file(
path_or_fileobj=file_path,
path_in_repo=file_name,
repo_id=repo_id,
repo_type="dataset"
)
print(f"Successfully uploaded {file_name}")
manage_backups(api, repo_id)
except Exception as e:
print(f"Error uploading file: {str(e)}")
# 下载最新备份
def download_latest_backup(token, repo_id, extract_path):
try:
api = HfApi(token=token)
files = api.list_repo_files(repo_id=repo_id, repo_type="dataset")
backup_files = [f for f in files if f.startswith('backup_') and f.endswith('.tar.gz')]
if not backup_files:
print("No backup files found")
return
latest_backup = sorted(backup_files)[-1]
with tempfile.TemporaryDirectory() as temp_dir:
filepath = api.hf_hub_download(
repo_id=repo_id,
filename=latest_backup,
repo_type="dataset",
local_dir=temp_dir
)
if filepath and os.path.exists(filepath):
with tarfile.open(filepath, 'r:gz') as tar:
tar.extractall(extract_path) # 解压到指定路径
print(f"Successfully restored backup from {latest_backup}")
except Exception as e:
print(f"Error downloading backup: {str(e)}")
if __name__ == "__main__":
action = sys.argv[1]
token = sys.argv[2]
repo_id = sys.argv[3]
if action == "upload":
file_path = sys.argv[4]
file_name = sys.argv[5]
upload_backup(file_path, file_name, token, repo_id)
elif action == "download":
extract_path = sys.argv[4] if len(sys.argv) > 4 else '.' # 默认为当前目录
download_latest_backup(token, repo_id, extract_path)
EOL
# 首次启动时从HuggingFace下载最新备份(解压到应用目录)
echo "Downloading latest backup from HuggingFace..."
python hf_sync.py download "${HF_TOKEN}" "${DATASET_ID}" "./"
# 同步函数
sync_data() {
while true; do
echo "Starting sync process at $(date)"
# 确保数据目录存在(选择你的实际路径)
STORAGE_PATH="./storage" # 或改为"./storage"
if [ -d "${STORAGE_PATH}" ]; then
# 创建备份
timestamp=$(date +%Y%m%d_%H%M%S)
backup_file="backup_${timestamp}.tar.gz"
# 压缩目录(使用-C避免包含父路径)
tar -czf "/tmp/${backup_file}" -C "$(dirname "${STORAGE_PATH}")" "$(basename "${STORAGE_PATH}")"
# 上传到HuggingFace
echo "Uploading backup to HuggingFace..."
python hf_sync.py upload "${HF_TOKEN}" "${DATASET_ID}" "/tmp/${backup_file}" "${backup_file}"
# 清理临时文件
rm -f "/tmp/${backup_file}"
else
echo "Storage directory ${STORAGE_PATH} does not exist, waiting..."
fi
# 同步间隔
SYNC_INTERVAL=${SYNC_INTERVAL:-7200}
echo "Next sync in ${SYNC_INTERVAL} seconds..."
sleep $SYNC_INTERVAL
done
}
# 启动同步进程
sync_data &
# 启动主应用(根据实际路径调整)
exec bash install_reader.sh # 或改为你的启动命令
并且修改README.md,在最后加入一行app_port: 8080
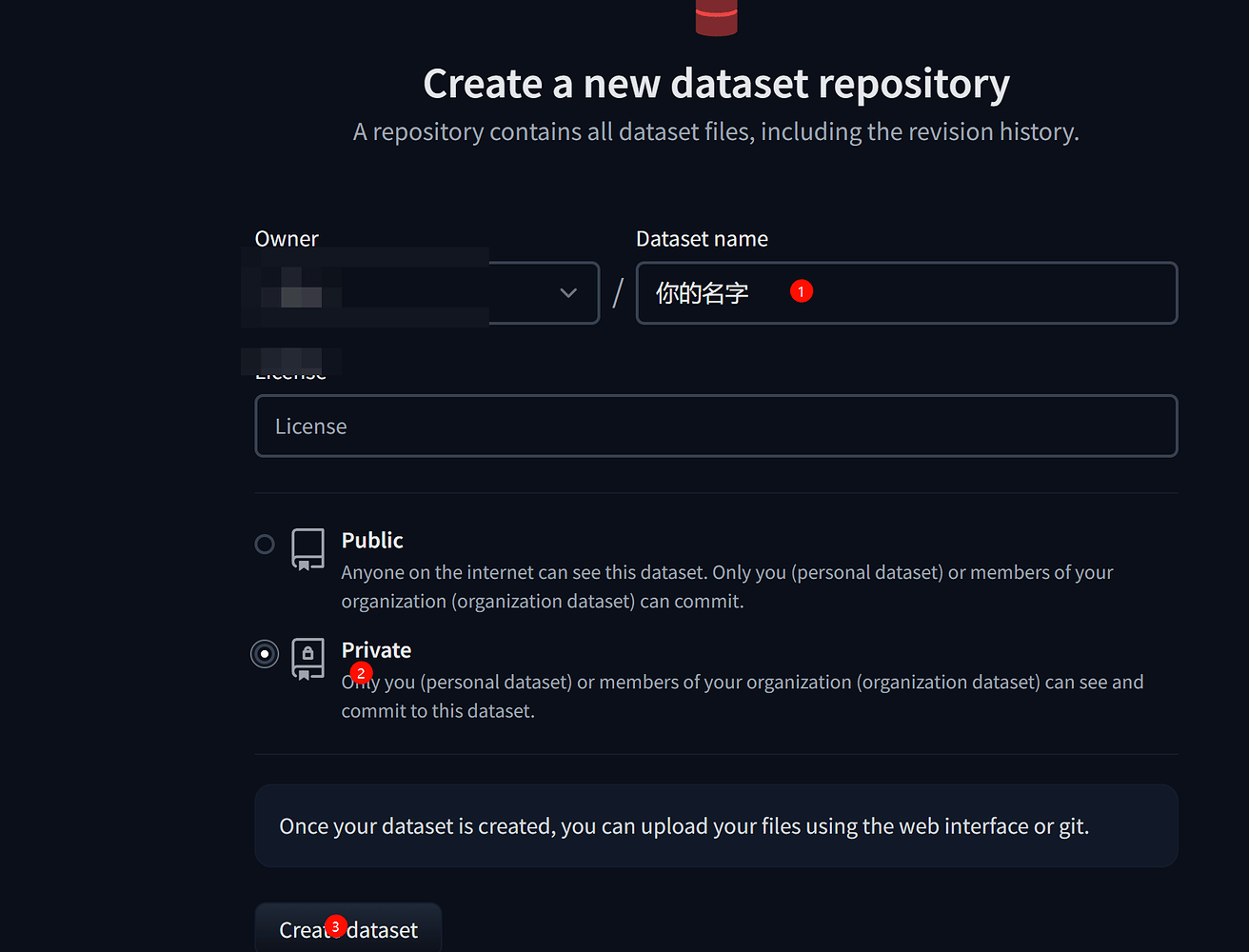
创建dataset数据库
image
image
记住你的数据库地址,格式:hugging名称/dataset名称
创建HF-token
image
image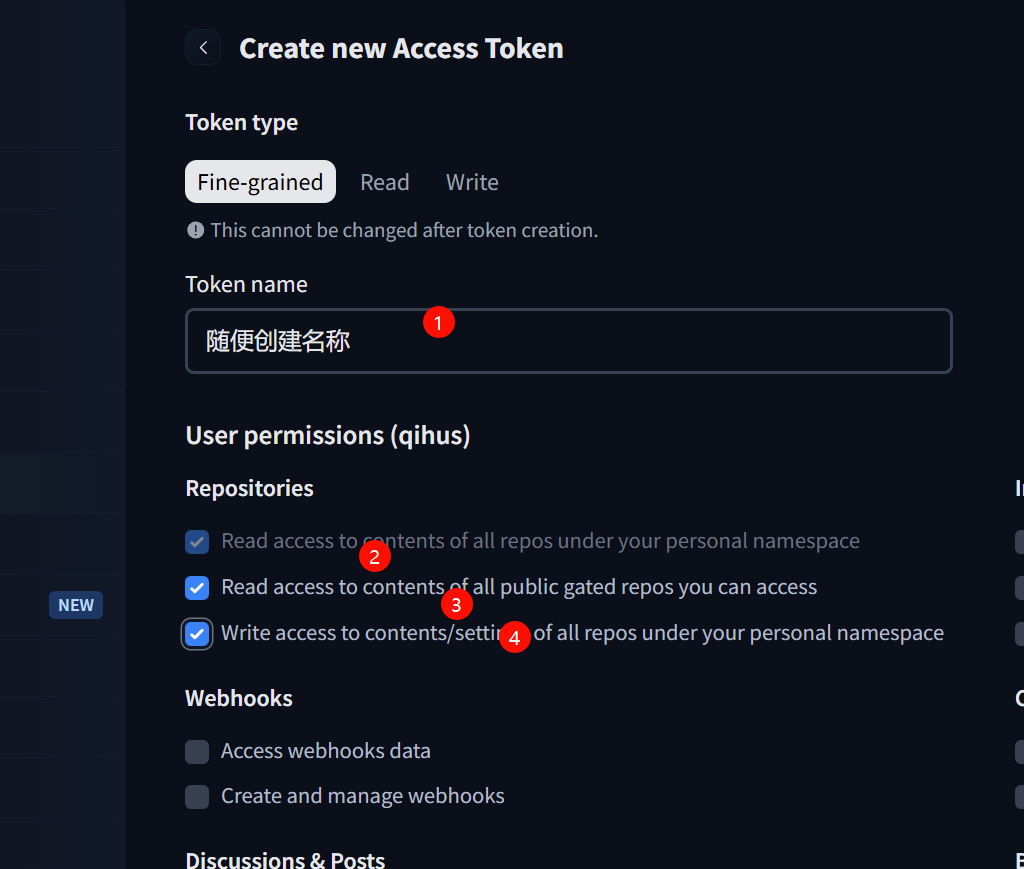
image
在后台添加环境变量
HF_TOKEN #你的token
DATASET_ID # 用户名/数据集名称
SYNC_INTERVAL # 同步时间(秒钟)例如3600
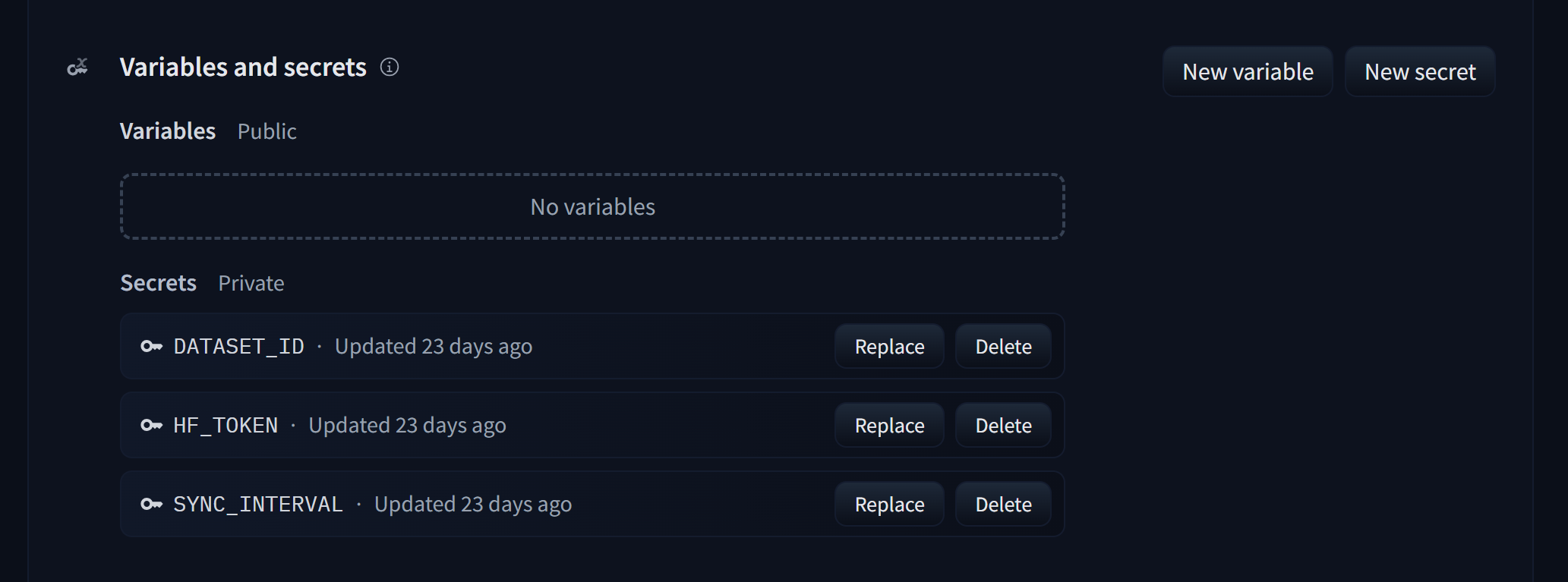
image
访问
现在在看到你的空间状态变为running后访问app选项卡应该就可以看到你的阅读服务器网页了
公开空间
下面,如果你的空间是公开空间,访问https://用户名-空间名.hf.space 就能访问到你的应用了
如果想要使用自己的域名,可以使用cf workers反代
export default {
async fetch(request, env) {
const url = new URL(request.url);
url.host = '你的地址';
return fetch(new Request(url, request))
}
}